オープンソース活用研究所 | 人工知能のビジネスへの活用法(TensorFlow活用例)
オープンソース活用研究所 | 人工知能のビジネスへの活用法(TensorFlow活用例)




2017年03月23日
オープンソース活用研究所 所長 寺田雄一
2017年1月18日に『人工知能をどうビジネスに活用するか?~オープンソースのディープラーニング「TensorFlow」の活用例から考える~』セミナーが開催されました。
急速に発展する人工知能技術をビジネスに活用する方法について、「TensorFlow」活用例を交えながら、2つの講演+ミニパネルディスカッションが行われました。
本記事では、次の3部構成で、セミナー内容をレポートします。
・第1部 セッション「Tensorflowとディープラーニング、ビジネスでの活用例」
・第2部 セッション「いち早く人工知能テクノロジーを取り入れた 製品・サービスを市場に展開するには?」
・第3部 ミニパネルディスカッション「人工知能をどうビジネスに活用すればよいのか」
株式会社KSKアナリティクス 高木 宏明 氏によるセッション「Tensorflowとディープラーニング、ビジネスでの活用例」をレポートします。
・機械学習とは
・深層学習(ディープラーニング)とは
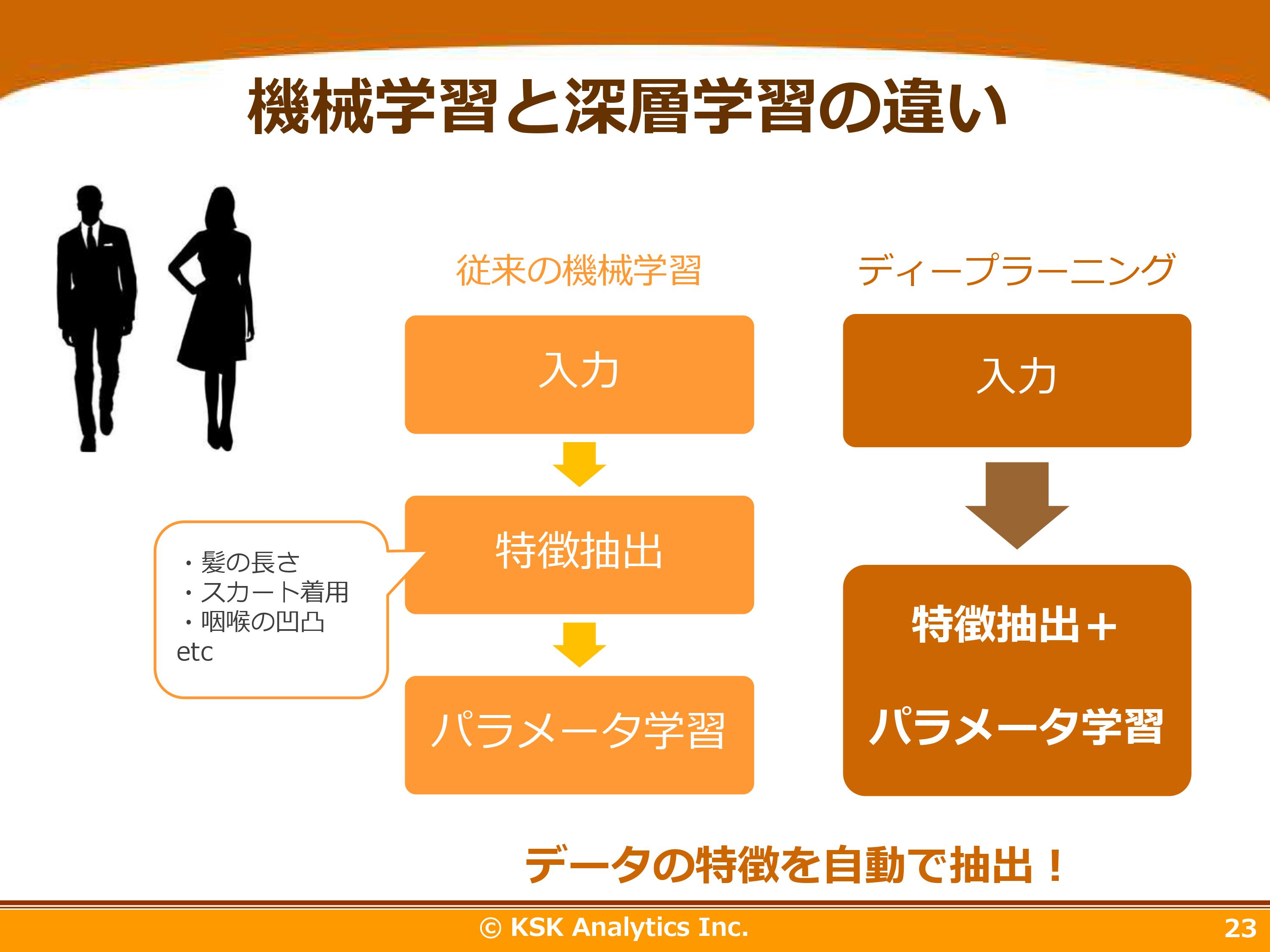
・従来の機械学習と深層学習の違い
・TensorFlow紹介
・何でもかんでもディープラーニング?
機械学習とは、入力データ(稼動ログ、センサーデータなど)から機械学習手法で学習モデルを作成し、入力パターンや規則性についてアルゴリズムを使用して学習を行なう手法です。
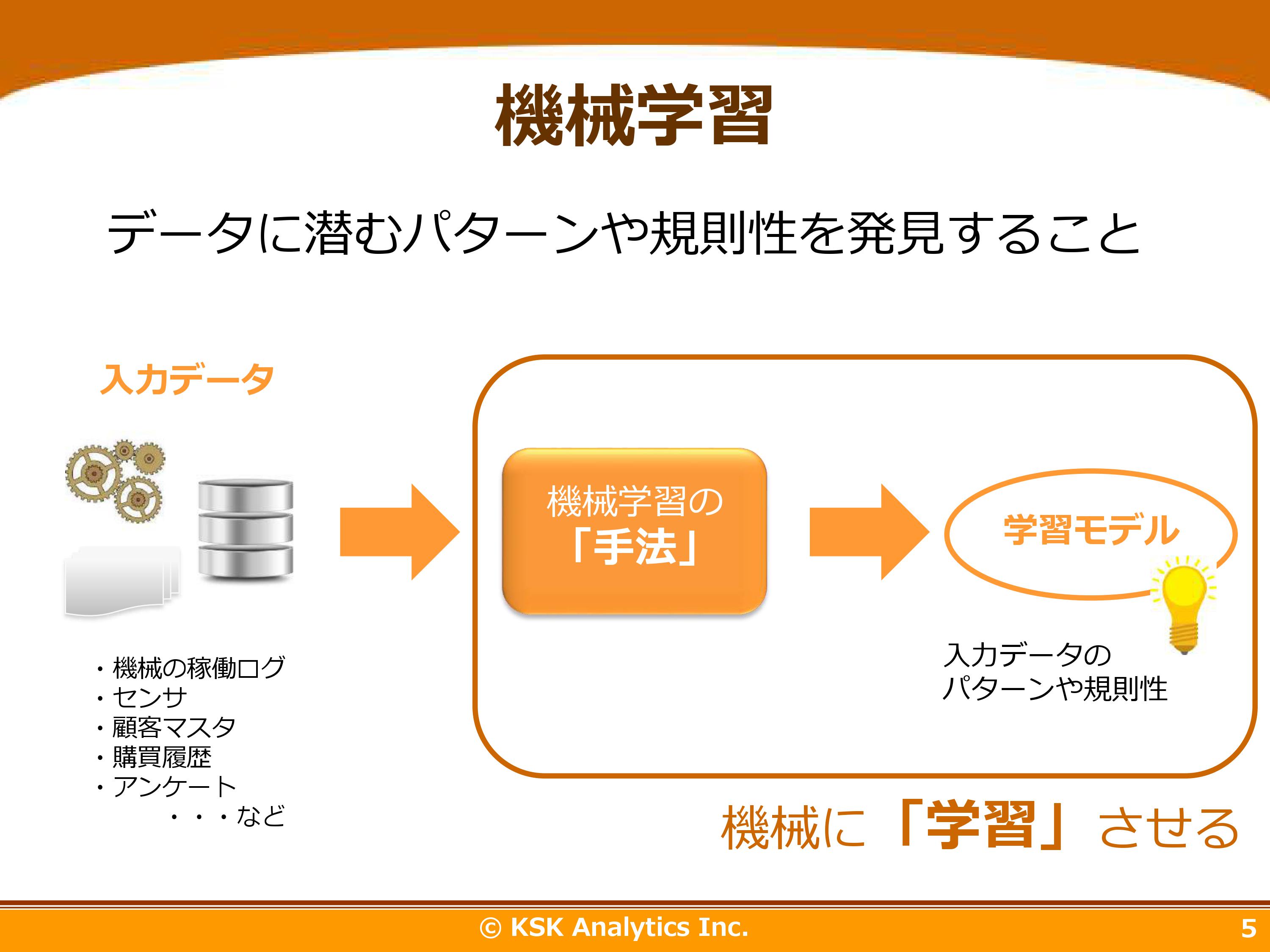
さまざまな機械学習手法がありますが、ディープラーニング手法は機械学習手法の中の1手法です。機械学習手法の一部であるニューラルネット手法の一部です。
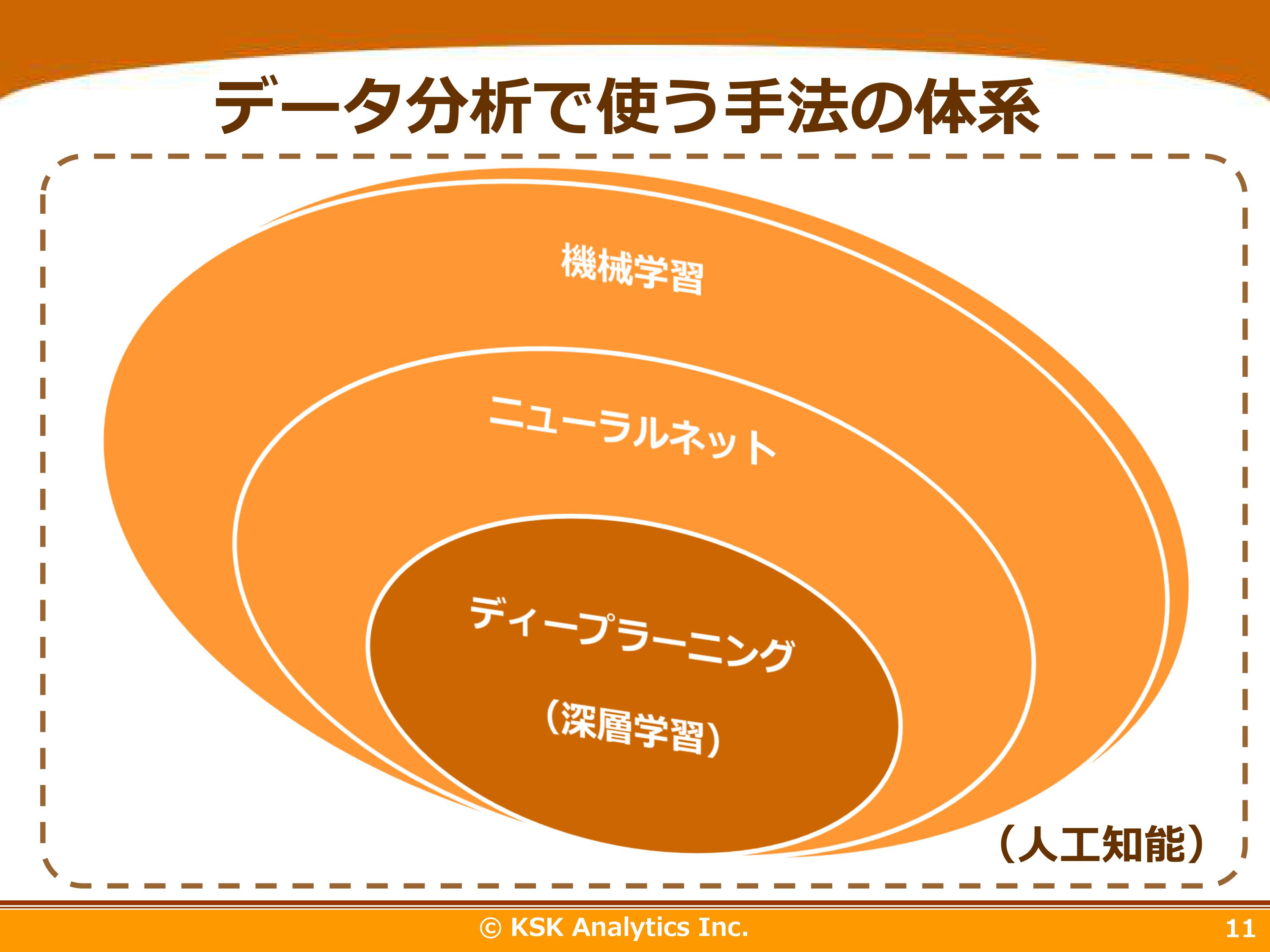
多くの分析手法が存在しています。
分析手法の採用は「マーケティング分野」や「金融分野」で進んでいます。「売上への結びつきが分かりやすい」「データが数値として揃っている」などの条件が整っている分野です。
一方、製造業分野(IoTなど)でのデータ分析は遅れている実感があります。

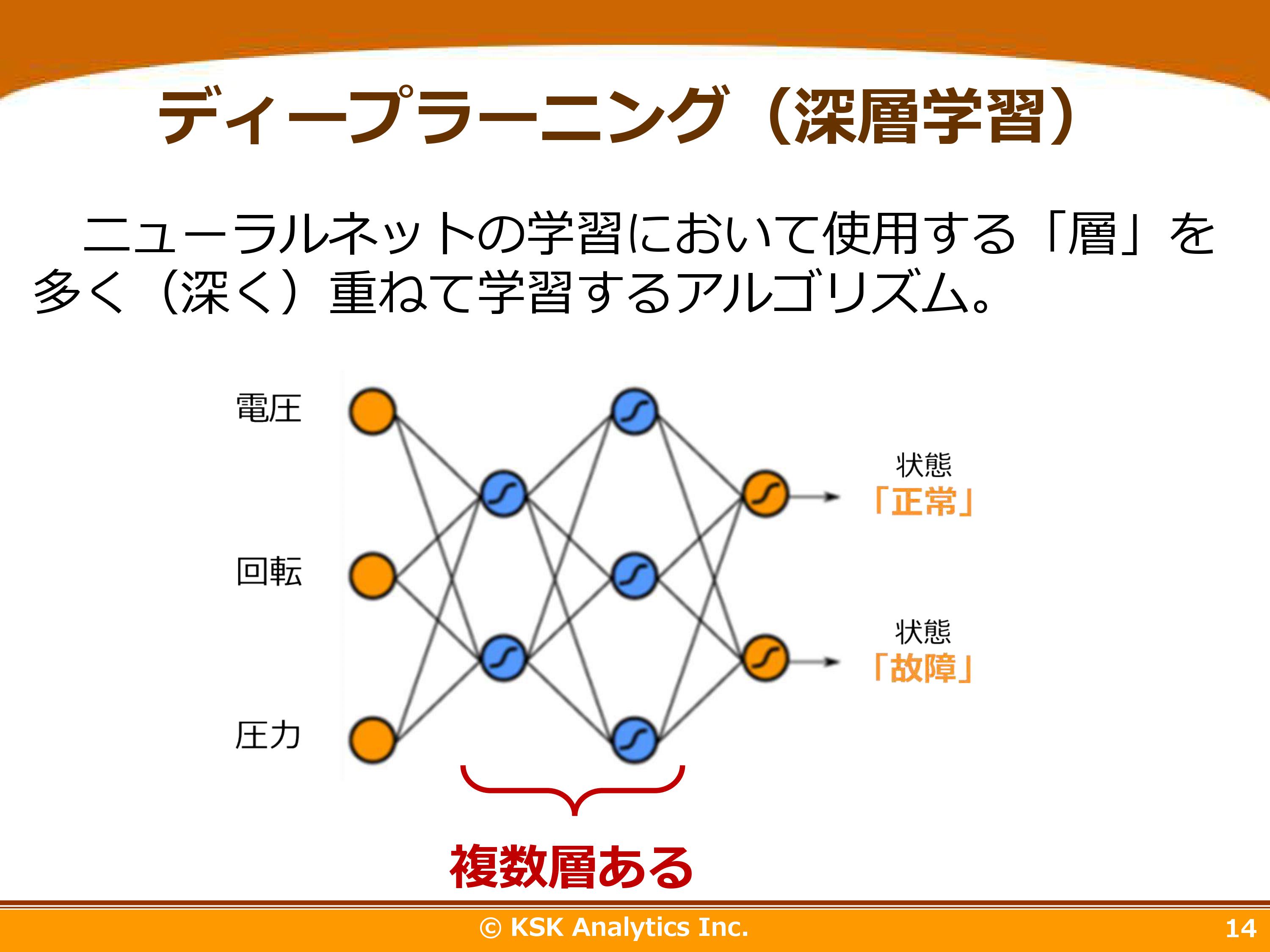
ニューラルネットの「層」を重ねるとディープラーニングになります。「層」を増やしていくことで、予測精度を上げることが可能です。
ディープラーニングは難易度が高い手法です。
[主な理由]
1.ネットワーク構成は日進月歩
海外の論文を読みながら理解するだけの知識が必要です。
2.鬼門パラメータチューニング
力技が一切使えないため、さまざまなテクニックを駆使しなければならない非常に高度な職人技です。
3.日本語の情報源が少ない
ディープラーニングの特徴は「人間の指示を必要としない特徴抽出」です。人間にも因果関係が分からないような分野に向いています。
TensorFlowのポイントは「グラフ」という概念です。ノード(演算処理)を線で接続して処理の流れを表現します。
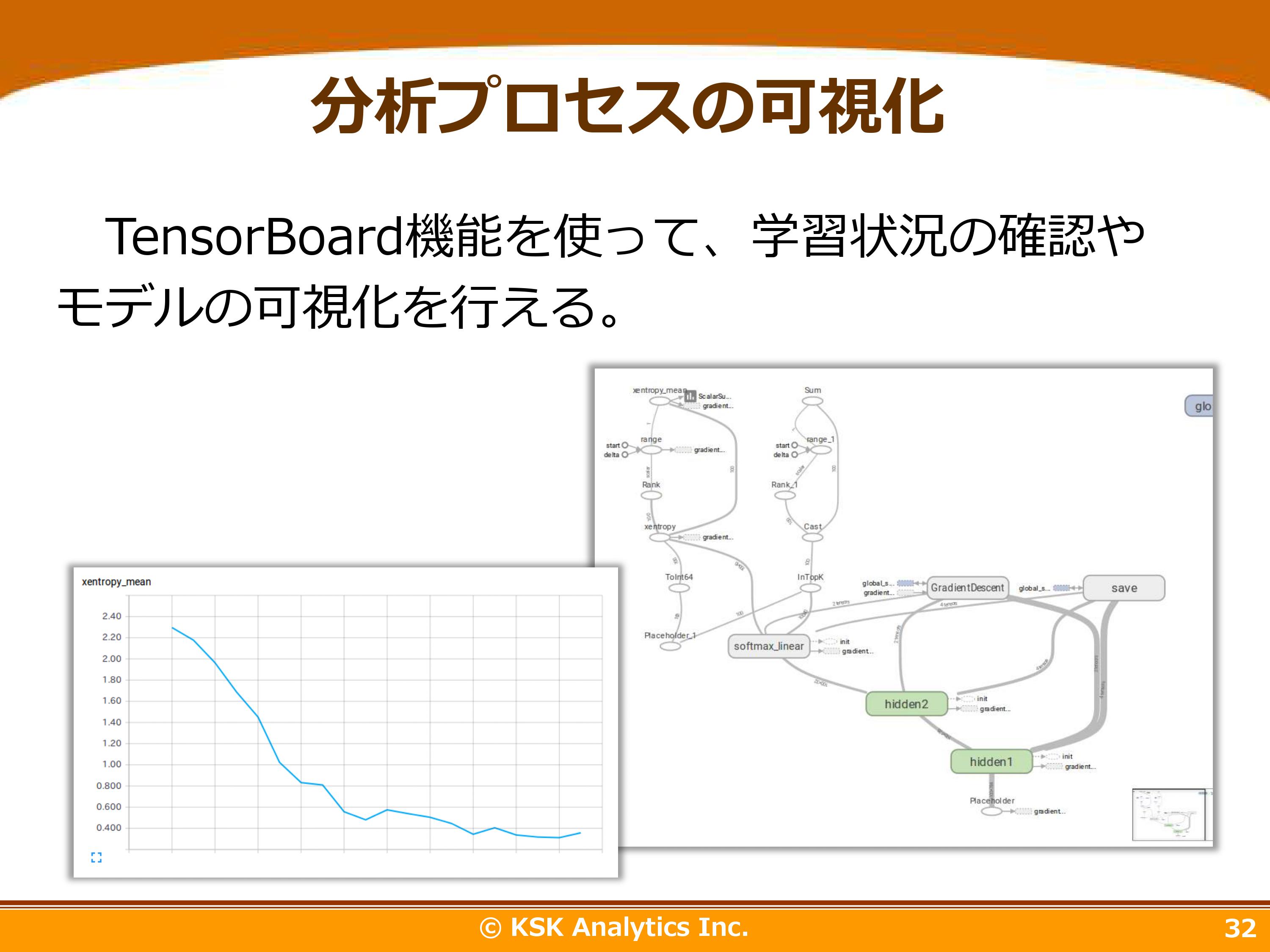
TensorFlowの優れている特徴として「TensorBoard機能」があります。「学習状況の確認」や「モデル可視化」などのビジュアル表現が可能です。
TensorFlowには「柔軟性が高い」という特徴があります。
その半面、データ分析手法に関する各種基礎知識(微分/積分知識、最新機械学習手法の理解など)を必要とするため、難易度はかなり高めです。
ディープラーニングは、因果関係が分かっていない分野の分析に向いています。
逆に、因果関係が分かっている分野については、従来の機械学習のほうが効率的に処理できます。
本セミナーの講演資料は、こちらからダウンロードできます。
→マジセミ →人工知能をどうビジネスに活用するか?~オープンソースのディープラーニング「TensorFlow」の活用例から考える~
このセッションの講演資料スライドには、「テクノロジー進化」「ビジネス活用へのポイント」「テクノロジーによる業界構造変化」など、AIに関するさまざまな最新情報について、詳細に分かりやすく解説されています。
全76ページもの非常に有益な資料となっていますので、ダウンロードしてご活用ください。
株式会社XEENUTS 西田 泰彦 氏によるセッション「いち早く人工知能テクノロジーを取り入れた製品・サービスを市場に展開するには?」をレポートします。
・両社の紹介について
・ソリューションマップ
・DeepLeaningを行うためのプロセス
・Deep Leariningの応用分野
・DeepLearning/ AIの進めかた
・対象分野リスティング
・データ投入/ トレーニング支援
・DeepLearningご提案にあたってのメニュー
・プロトタイプ作成支援以降
・DeepLearning/ AIのポジショニング
・AIトレーニング環境の整備 - HPE様 -
・AIトレーニング環境の整備 - IBM様 -
iPhoneで「Siri」などを使っている方は多いと思います。
ディープラーニングそのものは、すでに研究分野ではなく、製品に組み込まれている実用技術です。
AI/ディープラーニング/TensorFlowについて、非常に誇大広告されている面があります。私達は、これらの夢をたたみながら、組織の中に適用するビジネスを行っています。
「何ができますか?」ではなく「お困りのことは何ですか?」と身の回りの事象を解決していく方策に立つことにより、前に進むと考えています。
私達が進める作業の流れはこのように行います。
「プロジェクトメンバー候補の方々への社内勉強会」と「今後の進め方の検討」を行います。「事業決済責任者を含めて、1つの方向性にみんなで向かう」ということが目的です。
ディープラーニング適用項目候補の実現性の可否検討などを行います。
プロトタイプを始めて、AIの教育を行います。
クラウドでAIトレーニングを行えるようになってきていますが、次のような課題もあります。
・多くの処理を行なうとオンプレよりコストがかかるパターンがある
・ネットワーク帯域の問題
・機密データをクラウドにUPできない など
高度なAIトレーニングを行う場合には、高速GPUを搭載したサーバが必要になってきます。
最近では、専用サーバがかなり安く出てきています。
AIだけでできることには限りがあります。基本的にできることは認知だけです。
企業のアプリケーションにおいては、AI(ディープラーニング)のみで、すべて片付くわけではありません。
レガシーの仕組みとの併用によって、絶大な効果を発揮していくと考えています。
すでに「学習済サービス(ディファインドクラウド)」や「実績がある音声解析サービス」などが登場しています。
「企業に必要な知見を機械化するための特化AI」を作成し、既存サービスも組み合わせることにより、できるだけ早いタイミングで、皆様に使っていただけるようにお手伝いをさせていただいています。
私達は、日本におけるディープラーニングは「日本企業が抱える課題を解決するための術」になると思っています。
特に、既存事業の知見検証の部分において、「事象に対して正解が定義できるもの」に対して機械化をすることにより、「ナレッジを配布していく」概念を作れると考えています。
「人手を介さず認知を行なう」がキーワードです。
第3部のミニパネルディスカッション「人工知能をどうビジネスに活用すればよいのか」では、質問者からの質問に対して、以下の3名の方が回答する形で進行します。
・株式会社KSKアナリティクス 高木 宏明 氏
・株式会社XEENUTS 西田 泰彦 氏
・株式会社クラスキャット 佐々木 規行 氏
1.TensorFlowが注目されている理由として何があげられるでしょうか?
2.事業展開のリスク面を考慮する場合、オープンソースディープラーニングライブラリ(Chainer、Caffeなど)において、今後、どの製品を選択するべきでしょうか?
日本人ならChainerも
日本語書籍が充実しているという点から、日本人ならChainerを使うのが一番よいのではないかと、僕は思っています。
しかし、開発元であるPreferredさんの仕様に従う形になるリスクも考えられます。
[TensorFlowのメリット]
1.今後ドキュメントが充実していくと考えられる
2.Googleのクラウドプラットフォームとの親和性が高い
[TensorFlowはデバイスの中に埋め込める]
TensorFlowは「デバイスの中に実行環境を埋め込むことができる」点が大きなポイントだと思います。
金融分野において、実際に、ディープラーニングが非常に有効だったケースについてお聞きしたいと思います。
弊社で、金融分野でのケースはあまりありません。
[大統領の基調演説分析]
有名なケースとしては、大統領の基調演説をライブで分析して、声のトーンや文脈から、次の話題がGoodNewsなのかBadNewsなのかを予測して、先行して株の売買を行なう、ということがあります。
[AI株運用]
AI株運用は主流になってきています。日本でも、何社かベンチャーが出てきています。
弊社は、金融分野の案件はまだありません。
複数の口座サービスを提供している企業から、「入金との消込に基づいた上での資金繰り予測」などの相談はいただいています。
データサイエンティストを育てたいと思った場合、「ITが強い人間に業界専門技術を学ばせる」のと、その逆で「業界専門技術が強い人間にITを学ばせる」では、どちらがよいのでしょうか?
[スーパーマンはいない]
「どのように育成したらよいのか分からない」というお話をよくいただきます。回答として「まず、スーパーマンはいない」「スーパーマンを取ろうとしても取れない」とお答えしています。
[データ分析特化人材とフォロー体制]
私は、「データ分析に特化した人材を育成」するのがよいと思います。それぞれ個別の案件に関して、業務に詳しい人間がフォローする体制が必要です。
ただ、それでも人材育成は難しいと思います。
同じようなご依頼はたくさんいただいています。
[クラウドマシンラーニング環境]
パブリッククラウドベンダーが提供しているマシンラーニング環境を使えば、あまり負荷なくトライアルできます。
しかし、そのような環境はコモディティ化されたものを対象としているため、企業の匠レベルまでは到達できません。
[人材育成は必要]
そのため、ハードルが高いとされているデータ分析エンジニアを育成する必要があります。我々は、そのお手伝いさせていただいています。
[困難なラベル貼り付け作業]
ディープラーニングを行なう前の正常/異常のラベルを貼る作業は非常に手間がかかります。
[クラウドワークの活用]
アメリカでは「クラウドワーカーにラベルを貼っていただく」というビジネスが出てきています。今後、日本でも出てくると思います。
画像1枚について単価数円で、正常/異常のラベルを貼っていただくビジネスです。同じ画像に対して、違う3人でラベルを貼って、多数決を取ったものを正にして担保することも可能です。
1万枚の画像に対して、何百人~何千人でラベルを貼っていただいて、1日~2日で完成させるようなことができるようになってくると思います。
中小企業のAIへのチャレンジは、コスト面も含めて、どれくらい取り組まれているのでしょうか?
[ミニマムコスト]
コストについては、難易度で変わってくると思います。私は、1プロジェクトあたり、ミニマムで1000万円と見ています。
[学習済サービスの活用]
金額的に厳しい場合は、「学習済サービスを利用して、自分達でどのように活用できるかを考える」ことも1つの選択肢だと思います。
ビジネスの観点からすると、「AI分野に取り組んでいない企業は競争で徹底的に負けていく」ことは純然たる事実だと考えています。
[スーパー業界「Amazon Go」]
「Amazon Go」という、レジ業務が一切不要なスーパーが出てきました。スーパーというビジネスモデルにおいて、コスト構造がまったく変わってしまいます。
それに加えて、リアルタイムレコメンデーションを行い、お客様ひとりひとりに合わせて、商品をおすすめしていきます。当然、お客様1人あたりの売上も上がっていきます。これを低コストで実現可能です。
このようなビジネスモデルの変化に対応できない既存の中堅スーパーは、すべて負けていなくなってしまうことが予想されます。
[自動車業界]
トヨタは自動運転を見据えて、人工知能に何千億円という投資を行っています。
[AI対応の二極化]
「AIに対して何千億円を投資する企業」と「AIはやらなきゃねというレベルの企業」に、完全に二極化しています。
進んでいる企業は5年程度前から投資を始めています。今から始めている企業は、少し遅いと感じています。「来年再来年にでも始めましょうかね」という企業は置き去りにされてしまう直感があります。
[危機意識の有無]
私は、このような二極化された温度差を感じています。
「AIに取り組んでいかないと、コスト構造でも売上でも勝てなくなってしまう」という危機認識を持てるかどうかの差だと思っています。
AIでのビジネスについての話です。
[「AI」は「ネジ」と同じ]
「AI」は、確かに、これから大きく未来を変える可能性があるとは思います。しかし、事業モデルにおいては、極論ですが、「ネジ」と同じです。
自分達の「ネジ」に絶大な付加価値を見出せるかどうか
先日、日本の「絶対に緩まないネジ」が、NASAに1個1000円で採用されました。NASAは、「絶対に緩まない」という点に1個あたり1000円の価値を付けます。
[AIで自社をドライブさせられるのか]
「AIに価値を見出し、事業コンポーネントの1つのパーツとして自社に組み込むことができるのか?」が一番のポイントだと思います。
例えば、金融業界において、中長期的な視点を見据えて、収益やROIを考えていく中で、他に勉強する必要がある新技術などありましたら、教えてください。
[今のボトルネックは何か?]
「何を目標にするか」よりは「今の自分達のボトルネックは何なのか?」がポイントだと思います。
「そのボトルネックを解消するために、どのようなマイルストーンで進めていくのか?」という考え方のほうが前に進みやすいと思います。
テクノロジーを離れて、ビジネスの観点で話をします。
[銀行業のブロックチェーン対応]
ブロックチェーンが登場してきた現状において、特に銀行の場合は「どのようにして、今の事業ポートフォリオを完全に入れ替えていけばよいか?」という問題だと思います。
旧態依然とした銀行業務から撤退していき、新興ビジネスに移っていかなければ、立ち行かなくなると思います。
方策としては、ブロックチェーンをやっているような決済ベンチャーを買収して、比重をそちらに切り替えていくことが、最も現実的な選択肢だと思います。
[テクノロジーの捉え方]
「既存のビジネスモデルから撤退して、新しいビジネスに移行していく」という意識で、テクノロジーを捉えるのが正しいのではないかと思っています。
機械学習/ディープラーニングをトレーニングするためには、それなりの「データの量」と「データの質」が必要です。
[必要なデータ量]
例えば、手書きの0~9をまともに認識させるために必要なデータ量として、約5万5千件必要です。
みなさんのノウハウをトレーニングするためには、この程度の規模感のデータ「量」と「質」が必要です。
[スタートまでに1~2年]
コンサルを開始すると、「これからデータを集めます」ということになって、スタートできるまで1~2年かかることがあります。
[まずはデータ収集を]
肝心なことは、会社の中にデータを蓄えることです。画像でも文字でも音声でも、必要と思われるデータについての収集が重要です。
データがなければ始めることはできません。
本セミナーの講演資料は、こちらからダウンロードできます。
→マジセミ →人工知能をどうビジネスに活用するか?~オープンソースのディープラーニング「TensorFlow」の活用例から考える~


1993年、株式会社野村総合研究所(NRI)入社。 インフラ系エンジニア、ITアーキテクトとして、証券会社基幹系システム、証券オンライントレードシステム、損保代理店システム、大手流通業基幹系システムなど、大規模システムのアーキテクチャ設計、基盤構築に従事。 2003年、NRI社内に、オープンソースの専門組織の設立を企画、10月に日本初となるオープンソース・ソリューションセンター設立。 2006年、社内ベンチャー制度にて、オープンソース・ワンストップサービス 「OpenStandia(オープンスタンディア)」事業を開始。オープンソースを活用した、企業情報ポータル、情報分析、シングルサインオン、統合ID管理、ドキュメント管理、統合業務システム(ERP)などの事業を次々と展開。 オープンソースビジネス推進協議会(OBCI),OpenAMコンソーシアムなどの業界団体も設立。同会の理事、会長や、NPO法人日本ADempiereの理事などを歴任。 2013年、NRIを退社し、株式会社オープンソース活用研究所を設立。

2022-11-15(火)13:00 - 13:55 「データ活用におけるクレンジングの課題 〜「データ連携ツールを使っても非エンジニアには負担」の解決策〜」 と題したウェビナーが開催されました。 皆様のご参加、誠にありがとうございました。 **当日の資料は**以下から無料でご覧いただけます。 ご興味のある企業さま、ぜひご覧ください。

「Octosuite」(オクトスイート)とは、高度な「GitHubフレームワーク」です。「GitHubパブリックAPI」を使用して、GitHubプラットフォーム上の「ユーザーアカウント」「リポジトリ」「組織」などのオープンソースインテリジェンスを効率的に収集できます。また、「再現可能な一連のクエリ」を作成して自動化できます。
「HeidiSQL」(ハイディ/ヘイディ/ハイジ)とは、「データベース管理」および「データモデリング」を実施可能な軽量クライアントツールです。Delphiで記述されWindows環境で動作します。「MariaDB」と「MySQL」のツールに属しています。
Theano(テアノ)とは、Python用数値計算ライブラリです。「コンピュータ代数システム」と「最適化コンパイラ」の機能を有しており、多次元配列を含む数式について「定義」「最適化」「評価」が可能です。ディープラーニング計算処理でよく利用されています。
Apache Superset(アパッチスーパーセット)とは、最新エンタープライズ対応の「ビジネスインテリジェンスWebアプリケーション」です。「軽量」「高拡張性」「直感的」を特徴としており、「シンプルな円グラフ」から「詳細な地理空間チャート」まで、さまざまなデータ探索や視覚化が可能です。
Torch(トーチ)とは、「機械学習ライブラリ」および「科学計算フレームワーク」です。GPUを活用する機械学習のための幅広いアルゴリズムを提供します。「ディープラーニング」や「コンボリューショナルネット」などのニューラルネットワーク技術に特化しており、「シンプルプロセス」「最大限の柔軟性とスピード」などを特徴としています。
Metabase(メタベース)とは、オープンソースのデータ可視化ツールです。シンプルかつ強力なビジネスインテリジェンスツールとして、さまざまなデータ表現形式による意思決定サポートのための知見を得られます。特別な技術的スキルを必要とせずに利用できるため、ビジネス現場ですぐに利用できます。
Adminer(アドミナー)とは、PHPで記述されたフル機能のデータベース管理ツールです。同様な機能を提供する「phpMyAdmin」とは異なり、ターゲットサーバにデプロイする準備ができている単一ファイルで構成されます。主要データベースをサポートし、豊富なプラグイン機能も用意されています。
Microsoft Cognitive Toolkit(CNTK)(マイクロソフトコグニティブツールキット)とは、Microsoftが提供するオープンソースの「統合ディープラーニングツールキット」です。※CNTKは消極的開発段階に入っており、「ONNX」の利用が推奨されています。
Jaspersoft(ジャスパーソフト)とは、オープンソースのビジネスインテリジェンス(BI)ツールです。複数のコンポーネントで構成されており、高機能BIレポーティングツールとして、高度にインタラクティブなレポートを作成できます。Webやモバイルアプリケーションに組み込める分析機能なども提供します。
Apache Storm(アパッチストーム)とは、オープンソースのビッグデータ処理フレームワークです。耐障害性に優れており、分散型によるニアリアルタイム高速処理を実現します。「不正検出」「クリックストリーム分析」「大量IoTデバイス監視」「ソーシャル分析」「ネットワーク監視」などのリアルタイム性が要求される用途に適しています。
Apache NiFi(アパッチナイファイ)とは、データフローオーケストレーションツールです。Webインターフェースでシステム間のデータフロー自動化定義を実施し、フローベースプログラミングコンセプトでのデータ処理(配信)システムを構築できます。データフロー管理自動化のための「IoTデータフローを見据えた双方向性」を特徴としています。
Apache Solr(アパッチソーラー)とは、オープンソースエンタープライズ検索プラットフォームです。ApacheLucene上に構築されており、「高速処理」「高信頼性」「拡張性」「分散インデックス作成機能」「負荷分散クエリ機能」「自動フェイルオーバー機能」などの特徴があります。
Pentaho Data Integration(ペンタホデータインテグレーション)はETLツールです。革新的なメタデータ駆動型アプローチを使用して、強力な「データ抽出」「データ変換」「データ読み込み」などを実行できます。開発経緯から「Kettle」とも呼ばれます。
Apache Spark(アパッチスパーク)とは、インメモリ高速分散処理プラットフォームで、大規模データ処理用統合分析機能を提供します。「高速」かつ「汎用的」であることを目標に設計されています。Java派生言語「Scala」で実装されており、各種高機能ライブラリを搭載しています。
MXNet(エムエックスネット)とは、フル機能のディープラーニングフレームワークです。最先端のディープラーニング技術「畳み込みニューラルネットワーク(CNN)」「長短期メモリネットワーク(LSTM)」などをサポートしており、AWSが公式サポートを表明したことで大きな注目を集めています。
Jupyter Notebook(ジュピターノートブック)とは、インタラクティブコンピューティング用Webベースノートブック環境です。ノートブック形式で段階的にプログラムを実行し、データ分析作業を行える対話型ブラウザ実行環境として利用できます。
Pentaho(ペンタホ)とは、BI(Business Intelligence)に必要なすべての機能が用意されているプロフェッショナル向けのオープンソースBIスイート製品です。「ETL」「OLAP」「クエリ」「レポーティング」「インタラクティブ分析」「ダッシュボード」「データマイニング」など、データ統合から分析までを一貫して実施できます。
RapidMiner Studio(ラピッドマイナースタジオ)とは、ビジュアルデータサイエンスワークフローデザイナーです。「機械学習」「データマイニング」「テキストマイニング」「特徴選択」「予測分析」などのさまざまなデータ分析処理をプログラミングなしで実施できます。
scikit-learn(サイキットラーン)とは、Pythonのオープンソース機械学習ライブラリです。機械学習アルゴリズムを幅広くサポートしており、「分類回帰クラスタ分析」「ニューラルネットワーク」「サポートベクターマシン」「ランダムフォレスト」「k近傍法」などを手軽に実装できます。
Enigma(エニグマ)とはブロックチェーンタイプの分散型計算プロトコルです。「シークレットコントラクト」を可能にする分散ネットワーク構築が可能で、Enigmaネットワーク内の「シークレットノード」が暗号化データに対して安全に計算を実行できます。
Elasticsearch(エラスティックサーチ)とは、全文検索エンジンです。マルチテナント、スキーマレスでクラウドに最適化されています。HTTP WebインターフェースとスキーマフリーのJSONドキュメントを備えており、さまざまなユースケースに対応できる分散型RESTful検索が可能です。
Kibana(キバナ)とは、全文検索エンジン「Elasticsearch」と連携して使用するデータ解析/可視化プラットフォームです。データ分析および検索ダッシュボードで、全文検索エンジン「Elasticsearch」用のオープンソースのデータ視覚化プラグインとして機能します。
Chainer(チェイナー)とは、日本製の深層学習フレームワークです。ニューラルネットワークを誤差伝播で学習するライブラリで、Pythonで柔軟に記述し学習させることができます。特徴として「柔軟性」「直感的」「高機能」の3つを掲げています。
Apache Kafka(アパッチ カフカ)とは、分散ストリーミングプラットフォームです。「Pull型」「高スループット」などの特徴があり、ストリーミングデータパイプライン構築に利用できます。分散環境において「高スループット」かつ「低レイテンシ」で、大規模データを高速に取り込み配信できるメッセージングシステムです。
Caffe(カフェ)とは、オープンソースのディープラーニングライブラリです。画像認識に特化しており、「高速動作」「GPU対応」「洗練されたアーキテクチャ/ソースコード」「開発コミュニティが活発」などの特徴があります。C++/Python/MATLABなどで使用できます。
Apache Hadoop(アパッチハドゥープ)とは、オープンソース大規模データ分散処理フレームワークです。「データ処理基盤」と「分散コンピューティング基盤」という2つの特徴を持つフレームワークとして大規模データを効率的に分散処理および管理できます。
Orange(オレンジ)とはデータマイニングソフトウェアです。初心者から専門家までのニーズに対応できる対話型データ分析ワークフローとして利用できます。「探索的なデータ分析」と「対話的なデータ視覚化」のためのビジュアルプログラミングフロントエンドを特徴としています。
TensorFlow(テンソルフロー)とは、Googleの機械学習/ディープラーニング/多層ニューラルネットワークライブラリです。データフローグラフを使用したライブラリで複雑なネットワークを分かりやすく記述できます。高い汎用性により研究レベルから実プロダクトにまで活用できます。
NGT(Neighborhood Graph and Tree for Indexing)とは、高次元ベクトルデータ高速検索技術です。ビッグデータ分析/ディープラーニング領域に活用できる技術として注目されています。
Hyperledger(ハイパーレッジャー)とは、オープンソース「ブロックチェーン技術推進コミュニティー」です。「Linux Foundation」が中心となり、世界30以上の先進的IT企業が協力して、ブロックチェーン技術/P2P分散レッジャー技術の確立を目指しています。
Eclipse Deeplearning4j(イクリプスディープラーニングフォージェイ)とは分散型深層学習ライブラリです。「Java」「JVM(Java仮想マシン)」「各種アルゴリズム」をサポートします。
Keras(ケラス)とは、Python実装の高水準ニューラルネットワークライブラリです。「TensorFlow」「Microsoft Cognitive Toolkit」「Theano」上で実行できます。
Talend Open Studio(タレンドオープンスタジオ)とは、ELTビジュアル開発ツール群です。コードを記述せずにETLプロセスを作成できる点が特徴です。
Pravega(プラベガ)とは、オープンソースの分散ストレージサービスです。連続した無制限のデータに対してストレージ抽象化を行う、分散コンピューティングコーディネーションフレームワークです。
Fess(フェス)とは、Javaベースの全文検索サーバです。検索エンジンとして「Elasticsearch」を利用します。「5分で簡単に構築可能」な導入容易性が特徴です。
Schema Registry(スキーマ レジストリ)とは、メッセージングシステム「Apache Kafka」ベースのストリームデータ基盤「Confluent Platform」の1コンポーネントです。一元的なスキーマ管理機能を提供します。
Apache Flink(アパッチフリンク)。分散ストリーム処理プラットフォームです。バッチ処理にも対応し、耐障害性/拡張性を備えたストリーム処理基盤です。
Apache Nutch(アパッチナッチ)。オープンソースのWebクローラフレームワークです。Apache Hadoopによる拡張性が特徴です。
Apache Drill(アパッチドリル)。ビッグデータに対応するスキーマフリーSQLクエリエンジンです。構造化データ/非構造化データなどのさまざまなデータソースに対して、直接SQLクエリを実行して結果を得ることができます。
Norikra(ノリクラ)。ストリームデータ処理エンジンです。リアルタイムイベントストリームデータに対して、SQLライク言語でスキーマレスなデータ処理が可能です。手軽に利用できる点が特徴です。
Apache ManifoldCF(アパッチマニフォールドシーエフ)。オープンソースクローラフレームワークです。インターネット上やイントラネット内のさまざまなサーバに保管されているドキュメントコンテンツ(Webページ/文書ファイル/DBデータなど)を収集し、それを検索エンジンに送ります。
Eclipse BIRT(エクリプス バート)。BIRTとは、Business Intelligence and Reportting Toolsの頭文字。Eclipse上で利用できるレポート開発環境



2021/03/04 セキュリティDAYS Keyspider資料
本資料を見るには次の画面でアンケートに回答していただく必要があります。


OSS×Cloud ACCESS RANKING




